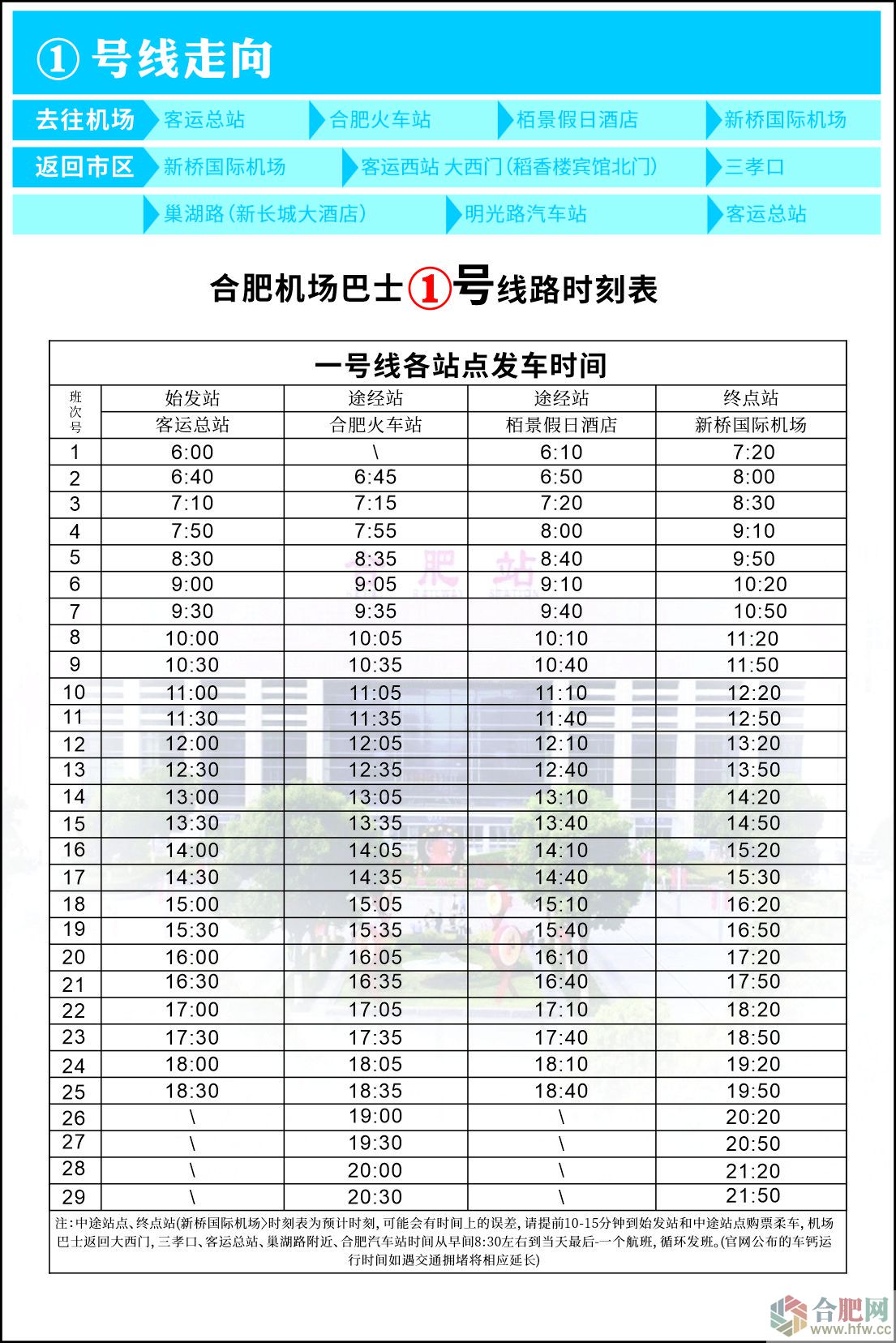
AM05 Workshop 2 - Data acquisition from Spotify API
Overview
In this workshop, you will learn how to:
Create a Spotify App Obtain the necessary credentials to access the Spotify API.
Request an Access Token Authenticate your app to interact with the API. Request Artist Data Fetch data for the UK's top 10 chart artists and their
songs.
Store Data in an SQL Database Design a simple database schema and insert the retrieved data.
Prerequisites:
Basic understanding of R programming.
R and RStudio installed on your computer.
Internet access.
A Spotify account (free account is sufficient).
No prior experience with APIs is required.
Optional: An SQL database system installed (e.g., MySQL, SQLite).
AM05 Workshop 2 Data acquisition from Spotify API 1
Table of Contents
Part 1 Setting Up Your Spotify Developer Account Step 1�� Create a Spotify Account
Step 2�� Create a Spotify App
Part 2�� Authenticating and Obtaining an Access Token Step 1�� Install Required R Packages
Step 2�� Set Up Authentication Credentials
Step 3�� Obtain an Access Token
Part 3�� Fetching Artist and Track Data
Step 1�� Identify the UK's Top 10 Chart Artists Step 2�� Retrieve Artist Data
Step 3�� Retrieve Tracks for Each Artist
Part 4�� Designing and Populating the SQL Database Step 1�� Define the Database Schema
Step 2�� Connect to the SQL Database from R Step 3�� Create Tables in the Database
Step 4�� Insert Data into the Database Conclusion
Appendix: Additional Resources
Part 1: Setting Up Your Spotify Developer Account
Step 1: Create a Free Spotify Account
If you don't already have a Spotify account:
���� Go to Spotify Sign Up.
���� Follow the instructions to create a free account.
Step 2: Create a Spotify App
���� Navigate to the Spotify for Developers Dashboard.
AM05 Workshop 2 �� Data acquisition from Spotify API 2
���� Log in with your Spotify account credentials. ���� Click on "Create an App".
Provide an App Name and App Description (e.g., "AM05 workshop").
Accept the Terms of Service and click "Create".
���� Your app will be created, and you'll be redirected to the app's dashboard.
Important:
Client ID and Client Secret:
On your app dashboard, you will see your Client ID.
Click on "Show Client Secret" to view your Client Secret.
Keep these credentials secure. Do not share them publicly or commit them to version control systems like GitHub.
Part 2: Authenticating and Obtaining an Access Token
To interact with the Spotify API, you need to authenticate your app and obtain an access token.
Step 1: Set Up Authentication Credentials
Create a file named .Renviron in your R project directory to store your credentials securely.
���� In RStudio, go to File > New File > Text File.
���� Add the following lines, replacing placeholders with your actual credentials:
���� Save the file as .Renviron in your project directory.
Note�� The .Renviron file is used by R to store environment variables securely.
Step 2: Install Required R Packages
Open R or RStudio on your computer. We'll use the httr and jsonlite packages for handling HTTP requests and parsing JSON data.
SPOTIFY_CLIENT_ID='your_client_id_here'
SPOTIFY_CLIENT_SECRET='your_client_secret_here'
AM05 Workshop 2 �� Data acquisition from Spotify API 3
install.packages("httr")
install.packages("jsonlite")
install.packages("tidyverse") # For data manipulation
Load the packages:
Step 3: Obtain an Access Token
Create a function to retrieve the access token.
library(httr)
library(jsonlite)
library(tidyverse)
get_spotify_access_token <- function() {
client_id <- Sys.getenv("SPOTIFY_CLIENT_ID")
client_secret <- Sys.getenv("SPOTIFY_CLIENT_SECRET")
response <- POST(
url = '<https://accounts.spotify.com/api/token>',
accept_json(),
authenticate(client_id, client_secret),
body = list(grant_type = 'client_credentials'),
encode = 'form'
)
if (response$status_code != 200) {
stop("Failed to retrieve access token")
}
content <- content(response)
return(content$access_token)
}
# Obtain the access token
access_token <- get_spotify_access_token()
AM05 Workshop 2 �� Data acquisition from Spotify API 4
Part 3: Fetching Artist and Track Data Step 1: Identify the UK's Top 10 Chart Artists
Since Spotify does not provide a direct API endpoint for charts, we'll manually list the UK's top 10 artists.
For this exercise, you can use the current UK Top 10 chart from a reliable source (e.g., Official Charts, BBC Radio 1��. For demonstration purposes, we'll use a sample list:
top_artists <- c(
"Ed Sheeran",
"Dua Lipa",
"Adele",
"Stormzy",
"Lewis Capaldi",
"Calvin Harris",
"Sam Smith",
"Little Mix",
"Harry Styles",
"Rita Ora"
)
Step 2: Retrieve Artist Data
Create a function to search for an artist and retrieve their Spotify ID.
get_artist_id <- function(artist_name, access_token) {
base_url <- '<https://api.spotify.com/v1/search>'
response <- GET(
url = base_url,
query = list(q = artist_name, type = 'artist', limit =
1),
add_headers(Authorization = paste('Bearer', access_toke
n)) )
if (response$status_code != 200) {
AM05 Workshop 2 �� Data acquisition from Spotify API 5
stop("Failed to retrieve artist data")
}
content <- content(response)
if (length(content$artists$items) == 0) {
warning(paste("Artist not found:", artist_name))
return(NA)
}
artist <- content$artists$items[[1]]
# Return a list with artist details
list(
id = artist$id,
name = artist$name,
followers = artist$followers$total,
genres = paste(artist$genres, collapse = ", "),
popularity = artist$popularity,
url = artist$external_urls$spotify
) }
# Retrieve data for all top artists
artist_data <- map_df(top_artists, ~ {
Sys.sleep(1) # To respect rate limits
artist_info <- get_artist_id(.x, access_token)
if (!is.na(artist_info$id)) {
return(as_tibble(artist_info))
} else {
return(NULL)
}
})
Explanation:
We define get_artist_id to search for an artist and extract relevant
information.
AM05 Workshop 2 �� Data acquisition from Spotify API 6
map_df from purrr (part of tidyverse ) applies the function to each artist in top_artists and combines the results into a data frame.
We include Sys.sleep(1) to pause between requests and respect API rate limits.
Step 3: Retrieve Tracks for Each Artist
Create a function to get the top tracks for each artist.
get_artist_top_tracks <- function(artist_id, access_token,
market = "GB") {
base_url <- paste0('<https://api.spotify.com/v1/artists/
>', artist_id, '/top-tracks')
response <- GET(
url = base_url,
query = list(market = market),
add_headers(Authorization = paste('Bearer', access_toke
n)) )
if (response$status_code != 200) {
stop("Failed to retrieve top tracks")
}
content <- content(response)
tracks <- content$tracks
track_list <- map_df(tracks, ~ {
list(
track_id = .x$id,
track_name = .x$name,
artist_id = artist_id,
album_id = .x$album$id,
album_name = .x$album$name,
release_date = .x$album$release_date,
popularity = .x$popularity,
duration_ms = .x$duration_ms,
AM05 Workshop 2 �� Data acquisition from Spotify API 7
track_url = .x$external_urls$spotify
)
})
return(track_list)
}
# Retrieve tracks for all artists
track_data <- map_df(artist_data$id, ~ {
Sys.sleep(1) # To respect rate limits
get_artist_top_tracks(.x, access_token)
})
Explanation:
get_artist_top_tracks fetches the top tracks for a given artist.
We use map_df to apply this function to each artist ID in artist_data .
Part 4: Designing and Populating the SQL Database
Step 1: Define the Database Schema
We'll design a simple relational database with the following tables: ���� artists
artist_id ��Primary Key) name
followers
genres
popularity
url ���� tracks
track_id ��Primary Key) track_name
artist_id ��Foreign Key)
AM05 Workshop 2 �� Data acquisition from Spotify API 8
album_id album_name release_date popularity duration_ms track_url
Note�� We establish a relationship between artists and tracks via the artist_id . Step 2: Connect to the SQL Database from R
For simplicity, we'll use SQLite, a lightweight, file-based database that doesn't require a server setup.
Install and load the RSQLite package:
Create a connection to an SQLite database file:
Step 3: Create Tables in the Database Create the artists and tracks tables.
install.packages("RSQLite")
library(RSQLite)
# Create or connect to the database file
con <- dbConnect(SQLite(), dbname = "spotify_data.db")
# Create 'artists' table
dbExecute(con, "
CREATE TABLE IF NOT EXISTS artists (
artist_id TEXT PRIMARY KEY,
name TEXT,
followers INTEGER,
genres TEXT,
popularity INTEGER,
url TEXT
) ")
AM05 Workshop 2 �� Data acquisition from Spotify API 9
# Create 'tracks' table
dbExecute(con, "
CREATE TABLE IF NOT EXISTS tracks (
track_id TEXT PRIMARY KEY,
track_name TEXT,
artist_id TEXT,
album_id TEXT,
album_name TEXT,
release_date TEXT,
popularity INTEGER,
duration_ms INTEGER,
track_url TEXT,
FOREIGN KEY (artist_id) REFERENCES artists (artist_id)
) ")
Explanation:
We use dbExecute to run SQL statements that modify the database structure. We define the data types for each column.
Step 4: Insert Data into the Database Insert data into the artists table.
# Insert artist data
dbWriteTable(
conn = con,
name = "artists",
value = artist_data,
append = TRUE,
row.names = FALSE
)
Insert data into the tracks table.
# Insert track data
dbWriteTable(
AM05 Workshop 2 �� Data acquisition from Spotify API 10
conn = con,
name = "tracks",
value = track_data,
append = TRUE,
row.names = FALSE
)
Verify the data insertion:
# Query the artists table
dbGetQuery(con, "SELECT * FROM artists")
# Query the tracks table
dbGetQuery(con, "SELECT * FROM tracks")
After you're done, close the connection:
Note: dbWriteTable automatically handles inserting data frames into the specified table.
Conclusion
Congratulations! You have successfully:
Set up a Spotify Developer account and created an app. Authenticated and obtained an access token.
Retrieved data for the UK's top 10 chart artists and their top tracks. Designed a simple relational database schema.
Inserted the retrieved data into an SQL database using R.
Bonus Step:
Extend the schema to include additional data (e.g., album details, track
features).
dbDisconnect(con)
AM05 Workshop 2 �� Data acquisition from Spotify API 11
Appendix: Additional Resources Spotify Web API Documentation:
https://developer.spotify.com/documentation/web-api/
httr Package Documentation: https://cran.r- project.org/web/packages/httr/httr.pdf
jsonlite Package Documentation: https://cran.r- project.org/web/packages/jsonlite/jsonlite.pdf
RSQLite Package Documentation: https://cran.r- project.org/web/packages/RSQLite/RSQLite.pdf
DBI Package Documentation: https://cran.r- project.org/web/packages/DBI/DBI.pdf
Official Charts: https://www.officialcharts.com/ Important Notes:
API Usage Compliance�� Ensure you comply with Spotify's Developer Terms of Service. Use the data responsibly and for educational purposes.
Rate Limiting�� Be mindful of API rate limits. Avoid making excessive requests in a short period.
Data Privacy�� Do not share personal or sensitive data. The data retrieved is publicly available information about artists and tracks.
Security�� Keep your Client ID and Client Secret secure. Do not share them or include them in publicly accessible code repositories.
Frequently Asked Questions
Q1�� I get an error saying "Failed to retrieve access token". What should I do?
A�� Check that your Client ID and Client Secret are correctly set in the .Renviron file. Ensure there are no extra spaces or missing quotes.
Q2�� The artist_data or track_data data frames are empty. Why?
A�� This could happen if the artist names are not found in the Spotify database. Ensure the artist names are correctly spelled. Also, check if the access token is valid.
AM05 Workshop 2 �� Data acquisition from Spotify API 12
Q3�� How can I view the data stored in the SQLite database?
A�� You can use SQL queries within R using dbGetQuery . For example:
# Get all artists
artists <- dbGetQuery(con, "SELECT * FROM artists")
# Get all tracks
tracks <- dbGetQuery(con, "SELECT * FROM tracks")
Alternatively, you can use a database browser tool like DB Browser for SQLite to view the database file.
Q4�� Can I use a different SQL database system?
A�� Yes. You can use other databases like MySQL or PostgreSQL. You'll need to install the appropriate R packages ( RMySQL , RPostgres ) and adjust the connection parameters accordingly.
Additional Exercises
To deepen your understanding, consider the following exercises:
���� Data Analysis�� Use SQL queries to find the most popular track among the top artists.
���� Data Visualization�� Create plots showing the popularity distribution of tracks or the number of followers per artist.
���� Extended Data Retrieval:
Fetch additional data such as album details or audio features of tracks. Update the database schema to accommodate the new data.
���� Error Handling:
Improve the robustness of your functions by adding more
comprehensive error handling and logging.
AM05 Workshop 2 �� Data acquisition from Spotify API 13
AM05 Workshop 2 �� Data acquisition from Spotify API 14
Ո��QQ��99515681 �]�䣺99515681@qq.com WX��codinghelp